
Bukan Pengganti, tapi Macroscope AI:
Panduan Kritis Menggunakannya dalam Riset Sejarah
Ketika Arsip Lebih Besar dari Satu Karir
Saat saya masih mengajar sejarah di sebuah SMA swasta di Jakarta Utara, ada satu pertanyaan yang sering saya pakai untuk membuka pelajaran tentang sumber sejarah: berapa buku yang bisa kalian baca dalam setahun, kalau benar-benar tekun? Jawaban yang muncul biasanya berkisar antara sepuluh dan dua puluh (saya sekitar 40-50 buku/tahun).
Saya kemudian menyebut satu angka yang biasanya membuat kelas terdiam: koleksi Koloniaal Verslag — laporan tahunan pemerintah kolonial Belanda yang terbit antara 1849 dan 1931 — saja sudah berisi puluhan ribu halaman. Itu baru satu jenis dokumen, dari satu lembaga, dalam satu rezim.
Di luar itu, ada Arsip Nasional Republik Indonesia dengan jutaan halaman dari era VOC sampai Orde Baru, koleksi digital KITLV di Leiden dengan puluhan ribu item, dan arsip surat kabar kolonial yang tersimpan dalam lemari-lemari raksasa di berbagai perpustakaan dunia.
Pertanyaannya: bagaimana satu peneliti bisa membaca semua itu? Jawaban yang jujur adalah: tidak bisa dan tidak mungkin.
Inilah paradoks yang hidup diam-diam di jantung penelitian sejarah. Semakin baik sebuah masyarakat dalam mendokumentasikan dirinya, semakin tidak mungkin satu peneliti membaca seluruh dokumentasinya.
Respons tradisional terhadap paradoks ini adalah seleksi: peneliti memilih sebagian kecil dari arsip yang tersedia, membacanya sangat teliti, dan dari sana membangun argumen.
Tidak ada yang salah dari strategi ini — ia melahirkan banyak karya besar. Tapi ia selalu meninggalkan satu pertanyaan yang tidak pernah bisa dijawab dengan jujur: apa yang ada di halaman-halaman yang tidak sempat dibaca?
Pertanyaan itulah yang mendorong saya, dan banyak peneliti lain, untuk mulai serius memperhatikan kemungkinan-kemungkinan baru yang ditawarkan oleh kecerdasan buatan. Tapi sebelum berbicara tentang janji, mari kita pelan-pelan dulu dengan satu metafora yang sangat berguna.
Macroscope: Alat untuk Melihat yang Sangat Besar
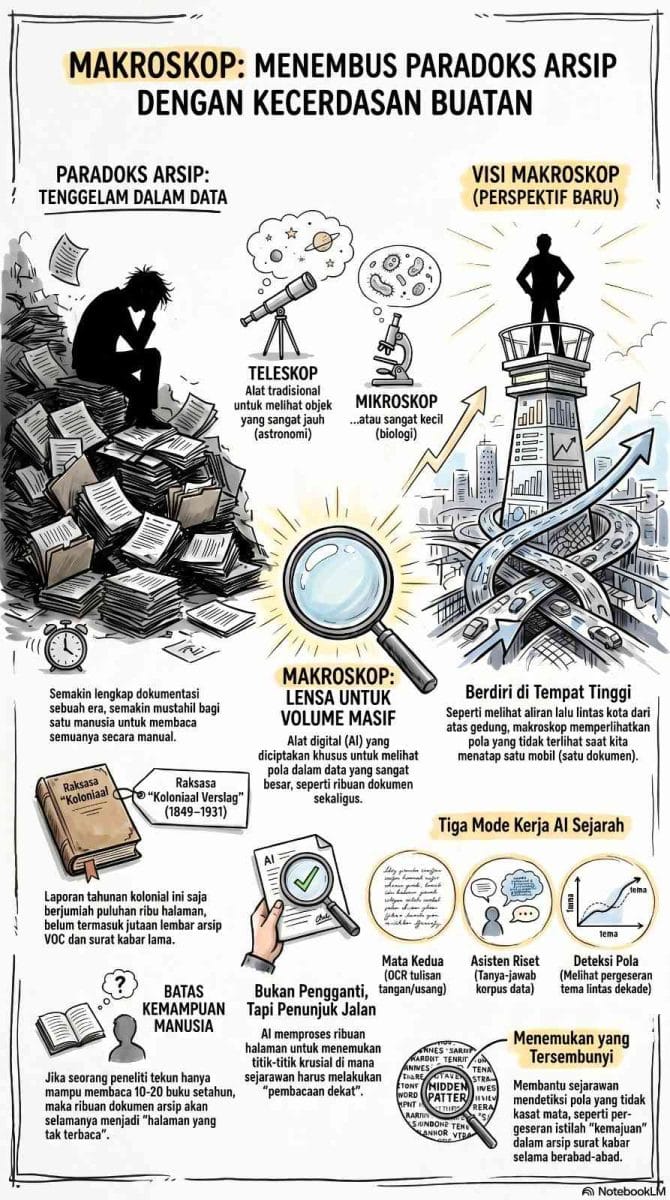
Ilustrasi paradoks arsip dalam penelitian sejarah: dari keterbatasan membaca puluhan ribu halaman Koloniaal Verslag secara manual, hingga penggunaan AI sebagai makroskop untuk melihat pola data masif dari kejauhan.
Pada 2016, tiga sejarawan digital — Shawn Graham, Ian Milligan, dan Scott Weingart — memperkenalkan istilah yang sejak itu terus dikutip dalam diskusi digital history: macroscope. Logikanya elegan dalam kesederhanaannya. Jika teleskop adalah alat untuk melihat yang jauh, dan mikroskop adalah alat untuk melihat yang kecil, maka macroscope adalah alat untuk melihat yang sangat besar. Bukan satu dokumen, melainkan sepuluh ribu. Bukan satu surat kabar, melainkan seluruh arsip surat kabar selama empat puluh tahun. Bukan untuk menggantikan pembacaan dekat, melainkan untuk menemukan titik-titik di mana pembacaan dekat layak dilakukan (Graham et al., 2016, hlm. xvi).
Ide ini sebenarnya bukan hal yang sepenuhnya baru. Sejak akhir abad ke-20, ahli sastra Franco Moretti telah memperkenalkan konsep distant reading — pendekatan yang berargumen bahwa untuk memahami pola dalam ribuan novel sejarahnya, kita justru harus mundur dari pembacaan satu demi satu (Moretti, 2000). Kalau pembacaan dekat ibarat membongkar mesin jam tangan, distant reading dan macroscope ibarat berdiri di puncak gedung dan melihat lalu lintas kota dari atas: ada pola-pola yang hanya muncul ketika kita berhenti menatap satu mobil dan mulai menatap aliran ribuan kendaraan.
Yang baru sekarang adalah mesin yang menggerakkan macroscope itu. Ketika Graham dan kolega-koleganya menulis bukunya, alat utama yang tersedia masih pemodelan topik klasik dan analisis kuantitatif sederhana. Sekarang, dengan kehadiran Large Language Models (LLM) seperti ChatGPT, Claude, dan Gemini, plus aplikasi turunannya seperti NotebookLM, macroscope mendapat tenaga komputasional yang jauh lebih kuat — sekaligus jauh lebih rumit untuk digunakan dengan baik (Henriot, 2025).
Artikel ini mencoba memetakan apa yang sebenarnya dilakukan AI dalam riset sejarah, dengan satu syarat: tidak menjual angan-angan. Setiap kemampuan baru selalu datang dengan keterbatasannya, dan keterbatasan itu — terutama untuk peneliti yang bekerja dengan sumber-sumber Indonesia — perlu dipahami sejelas kemampuannya.
Tiga Mode Kerja AI dalam Penelitian Sejarah
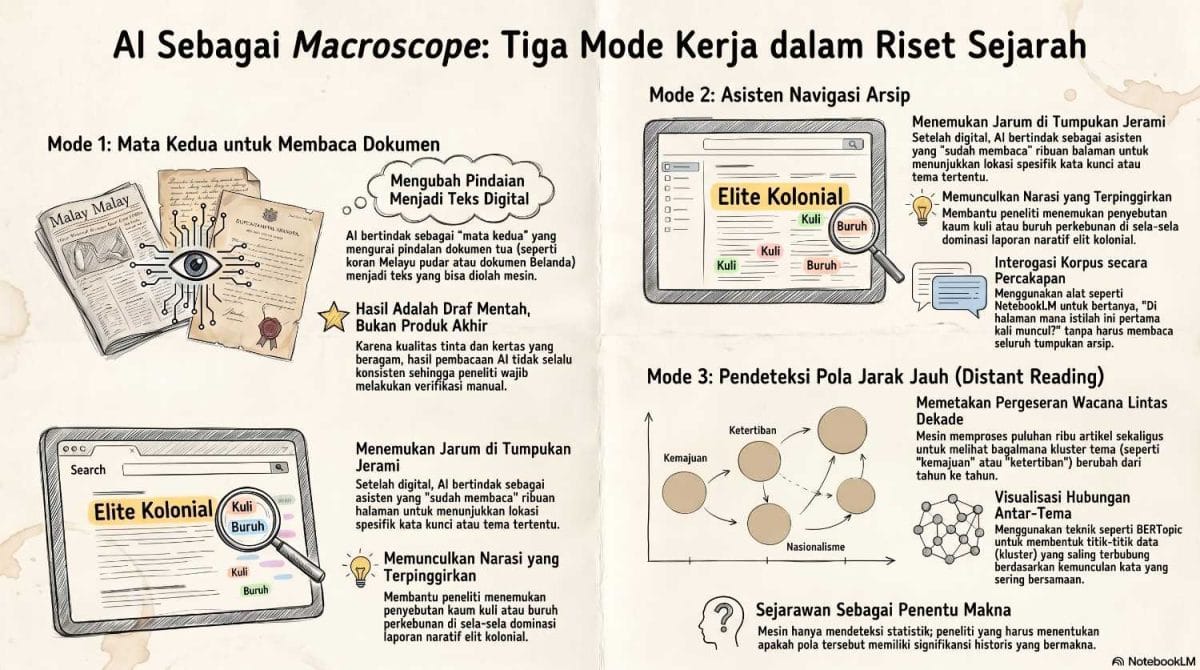
Tiga mode kerja fungsional AI: dari digitalisasi teks mentah (Mode 1), asisten ekstraksi informasi (Mode 2), hingga pendeteksian pola jarak jauh melalui distant reading (Mode 3).
Ketika orang berbicara tentang “AI untuk sejarah”, yang biasanya terbayangkan adalah satu hal tunggal — semacam kotak ajaib yang bisa diberi pertanyaan dan menjawabnya. Dalam praktiknya, AI bekerja dalam setidaknya tiga mode yang berbeda secara fungsi, kekuatan, dan keterbatasan masing-masing. Membedakan ketiganya adalah syarat pertama agar AI bisa benar-benar berguna dan tidak sekadar mengesankan.
Mode Pertama: Mata Kedua untuk Membaca Dokumen
Pernahkah kamu mencoba membaca tulisan tangan Belanda abad ke-19? Atau cetakan koran Melayu dari tahun 1920-an dengan tinta yang sudah memudar? Bagi siapa pun yang pernah mengerjakannya, kesulitan teknisnya langsung terasa di kepala dan di mata. Inilah titik paling awal — dan sering paling melelahkan — dari alur kerja sejarawan: mengubah pindaian dokumen menjadi teks yang bisa dibaca mesin.
Teknologi Optical Character Recognition (OCR) konvensional sudah lama membantu di sini, tapi ia sering tergagap ketika berhadapan dengan tulisan tangan, aksara yang tidak konsisten, atau cetakan dengan font usang. LLM mengubah kalkulasi ini, meskipun tidak menyelesaikannya sepenuhnya.
Stewart dan Sinha (2025), dalam Computational Humanities Research, mendokumentasikan satu pipeline tiga langkah yang mereka terapkan pada Plant Inventory Departemen Pertanian Amerika Serikat dari 1898 sampai 2008. Pertama, OCR mengubah pindaian menjadi teks kasar. Lalu segmentasi kustom memecah teks itu menjadi blok-blok yang bisa diproses. Lalu LLM mengekstrak informasi spesifik dari setiap blok. Hasilnya tidak seragam — model open-source menunjukkan performa yang tidak konsisten, dan validasi manual tetap diperlukan. Ini bukan kisah sukses tanpa syarat, melainkan pembuktian bahwa pipeline AI yang digabungkan dengan pengawasan manusia lebih realistis daripada otomasi penuh.
Pengalaman seperti itu mudah dikenali bagi siapa pun yang bekerja dengan dokumen kolonial berbahasa Belanda atau sumber-sumber berbahasa Melayu dalam aksara Arab-Jawi. Hasil OCR bisa sangat baik pada satu halaman dan menghasilkan kekacauan karakter pada halaman berikutnya — bergantung pada kualitas pindaian, konsistensi cetak, dan apakah model yang digunakan pernah “melihat” jenis dokumen itu dalam data pelatihannya. Ketidakkonsistenan ini bukan kegagalan teknologi yang bisa diselesaikan dengan memilih model yang lebih mahal; ia adalah sifat bawaan dari cara AI belajar membaca, dan ia menuntut peneliti untuk tetap memperlakukan setiap output sebagai draf yang perlu diperiksa, bukan produk akhir.
Mode Kedua: Asisten yang “Sudah Membaca” Ribuan Halaman
Setelah teks berhasil didigitalisasi, tantangan berikutnya adalah menemukan informasi spesifik dari dalamnya — nama, tanggal, relasi, peristiwa — tanpa membaca setiap halaman secara manual. Di sinilah LLM mulai menunjukkan nilai dramatis, sekaligus risiko yang lebih besar.
Gonzalez Garcia dan Weilbach (2023) mengajukan proposisi yang produktif: bagaimana jika ribuan sumber yang biasanya hanya tertumpuk di hard drive peneliti — dan tidak pernah sempat dibaca sepenuhnya — bisa dimasukkan ke dalam korpus khusus dan diinterogasi secara percakapan? Mereka menguji dua mode kerja: question-answering, yakni mengajukan pertanyaan kepada korpus sumber layaknya berdialog dengan asisten riset, dan extraction and organization of data, yakni menarik informasi terstruktur dari teks yang tidak terstruktur. Lebih baru lagi, Hufe dan koleganya (2026) dari Universitas Oxford mengembangkan Chronos, agen AI yang dirancang khusus untuk riset sejarah, dengan kemampuan mengadaptasi alur ekstraksi sesuai karakter sumber masing-masing tanpa peneliti harus menguasai pemrograman.
Untuk pembaca yang ingin mencoba versi lebih sederhana dan tanpa instalasi, NotebookLM milik Google mungkin titik masuk yang paling aksesibel. Sejarawan Lucas Poy (2025) menulis serangkaian refleksi setelah menggunakan NotebookLM pada arsip surat kabar sosialis abad ke-20, dan kesimpulannya penting untuk dicatat: alat ini berguna bukan untuk menggantikan pembacaan, melainkan untuk memunculkan petunjuk — tema, frasa, dan halaman-halaman yang patut diperiksa lebih dekat. Setelah petunjuk muncul, peneliti tetap kembali ke pembacaan dekat manual untuk interpretasi yang sungguhan.
Di sini cara kerja macroscope menjadi konkret dan terbayang. AI tidak mengganti pembacaan; ia memungkinkan peneliti menemukan titik mana yang layak dibaca lebih dalam dari arsip yang volumenya melampaui kemampuan baca tunggal. Anggap saja seperti seorang asisten yang sudah membaca seluruh tumpukan dokumen di mejamu — bukan untuk membuat kesimpulan, melainkan untuk menjawab ketika kamu bertanya: “Di halaman mana sebenarnya istilah ini pertama kali muncul?”
Mode Ketiga: Mendeteksi Pola yang Tidak Terlihat dari Dekat
Mode ketiga adalah yang paling dekat dengan visi macroscope yang awal — membaca bukan satu teks, melainkan ribuan teks sekaligus, bukan untuk memahami masing-masing secara mendalam, melainkan untuk melihat pola yang tidak terlihat dari jarak dekat.
Murugaraj dan koleganya (2025) mendemonstrasikan ini dengan BERTopic, teknik topic modeling berbasis transformer yang lebih kontekstual dari pendahulunya. Korpus mereka adalah arsip surat kabar historis tentang wacana nuklir 1955–2018. Dalam waktu komputasi yang relatif singkat, mereka bisa menelusuri bagaimana kluster tema bergeser dari dekade ke dekade — sesuatu yang secara praktis mustahil dilakukan melalui pembacaan manual terhadap puluhan ribu artikel.
Yang penting dari cara kerja ini, seperti yang sudah diingatkan Graham dan koleganya sejak awal, adalah bahwa label dan makna dari setiap “topik” yang dihasilkan mesin tetap harus ditentukan oleh peneliti, bukan mesin. AI menemukan kluster kata-kata yang sering muncul bersama; sejarawanlah yang memutuskan apakah kluster itu mencerminkan konsep historis yang bermakna. Mesin tidak tahu apa itu “kolonialisme” sebagai gagasan; ia hanya tahu kata “kolonial” sering muncul bersama kata “pemerintah”, “tanah”, dan “pribumi”. Sejarawan yang harus melihat pola itu dan bertanya: konsep historis apa yang melatari kemunculan bersama ini, dan mengapa baru muncul pada periode tertentu?
Empat Hal yang Tidak Bisa AI Lakukan — dan Mengapa Ini Penting
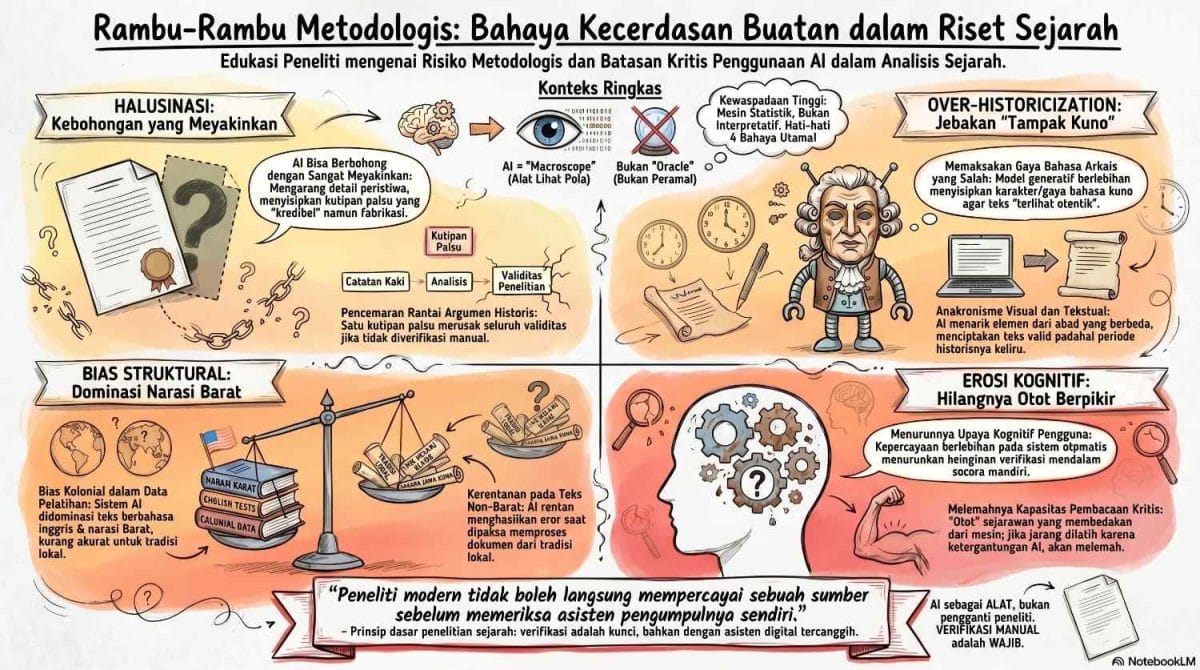
Empat bahaya utama penggunaan AI generatif secara naif dalam metode sejarah: halusinasi, over-historicization, bias kolonial, dan ancaman hilangnya daya kritis sejarawan.
Setiap bagian sebelumnya berakhir dengan sebuah “tapi”, dan itu bukan kebetulan. Penggunaan AI yang naif — tanpa pemahaman tentang apa yang tidak bisa dilakukannya — bisa lebih merusak daripada tidak menggunakannya sama sekali, karena ia menghasilkan kepercayaan yang tidak teruji.
Halusinasi: Ketika AI Berbohong dengan Meyakinkan
Masalah paling umum dan paling sering dijumpai dalam praktik adalah halusinasi: LLM menghasilkan teks yang terdengar sangat meyakinkan tapi sepenuhnya salah. Ia bisa mengutip sumber yang tidak ada, menyebut peristiwa dengan detail yang tampak presisi tapi difabrikasi, atau menggabungkan informasi dari dua konteks historis yang berbeda menjadi satu pernyataan yang tampak koheren.
Dalam riset sejarah, ini bukan gangguan kecil. Sebuah kutipan palsu yang masuk ke catatan kaki bisa mencemari seluruh rantai argumen — terlebih jika peneliti lain mengutipnya tanpa verifikasi. Sui dan koleganya (2024) memang menawarkan perspektif yang menarik tentang bagaimana halusinasi yang terkendali bisa berfungsi sebagai critical confabulation untuk merekonstruksi narasi yang hilang dari arsip — misalnya kisah-kisah subaltern yang dicoret dari dokumen resmi. Tapi proposal mereka justru mengukuhkan, bukan melonggarkan, satu prinsip kunci: halusinasi yang berguna adalah halusinasi yang sadar dan terikat-bukti, bukan halusinasi yang dianggap sebagai fakta. Jika sejarawan tidak bisa membedakan mana spekulasi dan mana data, AI bukan menjadi macroscope; ia menjadi kabut.
Over-Historicization: Bahaya Tampak “Kuno”
Masalah kedua lebih spesifik dan lebih jarang dibahas: over-historicization. Levchenko (2025) menemukan fenomena ini ketika mengevaluasi dua belas LLM multimodal untuk transkripsi dokumen Rusia abad ke-18. Beberapa model justru menyisipkan karakter arkais dari periode historis yang salah — mereka terlalu bersemangat “terdengar kuno” sehingga menarik elemen dari abad yang berbeda dari yang sedang ditranskripsi.
Ini adalah halusinasi paling berbahaya untuk sejarawan karena ia tidak tampak sebagai kesalahan. Ia tampak sebagai teks historis yang valid. Implikasinya untuk peneliti yang bekerja dengan dokumen yang merentang beberapa lapisan periode — misalnya laporan kolonial yang merujuk dokumen VOC yang lebih tua — cukup serius. Sebuah karakter yang dimasukkan AI dengan keliru bisa terlihat lebih “otentik” daripada teks asli, dan justru karena itu lolos dari pengawasan.
Bias Kolonial: AI yang Belum Membaca Kita
Masalah ketiga adalah yang paling struktural. Mohamed, Png, dan Isaac (2020), dalam makalah berpengaruh berjudul “Decolonial AI” yang diterbitkan di Philosophy & Technology, menunjukkan bahwa sistem AI menyematkan nilai dan struktur kekuasaan dari data yang digunakan untuk melatihnya. Data pelatihan LLM didominasi oleh teks berbahasa Inggris, berasal dari konteks Barat, dan merepresentasikan narasi sejarah yang sudah mapan secara global.
Artinya, ketika seorang peneliti Indonesia menggunakan LLM untuk menganalisis dokumen berbahasa Belanda abad ke-19, teks Melayu klasik, atau laporan dalam aksara Jawa Kuna, ia menggunakan alat yang belum pernah “melihat” banyak dokumen dari tradisi itu. Bias ini tidak lahir dari niat buruk siapa pun — ia adalah konsekuensi dari cara data pelatihan dipilih dan dari bahasa apa saja yang banyak terwakili di internet. Tapi konsekuensinya nyata dan konkret: AI cenderung lebih akurat untuk dokumen yang representatif dalam korpus dominan, dan lebih rentan terhadap error untuk dokumen dari tradisi bahasa dan tulisan lain. Ini bukan argumen untuk menolak AI; ini argumen untuk tidak mempercayainya secara buta ketika ia bekerja di luar domain yang sudah teruji.
Hilangnya Otot Berpikir
Ada satu masalah keempat yang lebih tersembunyi, tapi mungkin paling penting untuk masa depan profesi kita. Lee dan koleganya (2025) dari Microsoft Research dan Carnegie Mellon University mensurvei pekerja pengetahuan yang rutin menggunakan AI generatif, dan menemukan satu pola yang konsisten: kepercayaan pada AI berkorelasi dengan menurunnya upaya kognitif yang dilakukan pengguna sendiri. Semakin pengguna percaya bahwa AI akan memberi jawaban yang baik, semakin sedikit pengguna berpikir kritis tentang jawaban itu.
Untuk sejarawan, implikasinya jelas. Pembacaan kritis adalah otot yang kita bangun selama bertahun-tahun — dengan duduk berjam-jam di perpustakaan, dengan terbiasa curiga pada klaim yang terlalu mulus, dengan belajar menyukai catatan kaki. Kalau otot itu jarang dipakai, ia melemah. Risiko sebenarnya bukan AI mengganti sejarawan; risikonya adalah sejarawan berhenti melatih kapasitas yang justru membuatnya berbeda dari mesin. Ada perbedaan besar antara menggunakan macroscope sebagai alat dan menyerahkan otoritas analitis kita kepadanya, dan perbedaan itu hanya bisa dijaga oleh disiplin.
Konteks Indonesia: Permata yang Belum Tergarap
Indonesia memiliki salah satu korpus arsip kolonial terkaya di dunia — dan sekaligus salah satu yang paling underserved dalam perkembangan digital history global. Sebagian besar Koloniaal Verslag belum terdigitalisasi penuh. Ribuan laporan dari arsip VOC tersimpan dalam kondisi dan format yang heterogen. Aksara Jawa, aksara Bali, Melayu klasik dalam aksara Arab-Jawi — semuanya menunggu alat yang cukup matang untuk menjangkaunya.
Potensi AI di sini sangat besar, terutama untuk Mode Pertama dan Mode Kedua yang sudah dibahas. Bayangin BERTopic yang diaplikasikan pada arsip De Locomotief atau Bataviaasch Nieuwsblad untuk menelusuri bagaimana wacana tentang “ketertiban” atau “kemajuan” bergeser sepanjang periode tanam paksa hingga pergerakan nasional. Bayangkan NotebookLM yang diberi seluruh seri Koloniaal Verslag 1849–1931 sebagai korpus, lalu ditanya: kapan istilah kemajoean pertama kali muncul dalam laporan resmi, bagaimana frekuensinya berubah, dan dengan istilah apa ia paling sering berkoeksistensi? Ini bukan spekulasi futuristik; ini kemungkinan metodologis yang alat dan literatur teknisnya sudah ada hari ini.
Tapi hambatan yang dihadapi peneliti Indonesia — terutama peneliti mandiri tanpa akses ke institusi besar — berpusat persis pada masalah-masalah yang sudah dibahas. OCR yang tidak konsisten ketika berhadapan dengan kualitas pindaian yang bervariasi. Halusinasi yang meningkat ketika LLM diminta bekerja pada teks yang langka dalam data pelatihannya. Bias struktural yang membuat alat-alat ini lebih bekerja untuk Atlantic World daripada untuk East Indies. Pipeline seperti yang didokumentasikan Stewart dan Sinha (2025) tetap membutuhkan validasi manual yang tidak sedikit — dan validasi itu hanya bisa dilakukan oleh peneliti yang sudah cukup menguasai sumbernya untuk bisa mendeteksi ketika AI menghasilkan sesuatu yang janggal.
Justru di sinilah, paradoksnya, peneliti Indonesia berada di posisi yang strategis. Untuk dokumen Koloniaal Verslag atau surat kabar Melayu pra-kemerdekaan, peneliti Indonesia adalah salah satu kelompok yang paling layak untuk mendeteksi error AI — karena mereka sudah hidup dengan idiom, konteks, dan rujukan-rujukan yang membentuk sumber tersebut. Macroscope yang paling tajam tidak dibangun di Silicon Valley atau di kampus Amerika; ia dibangun di tangan peneliti yang menguasai sumbernya.
Macroscope, Bukan Orakel
Graham, Milligan, dan Weingart (2016) memberikan peringatan yang relevan jauh sebelum era LLM: macroscope hanya berguna di tangan peneliti yang sudah tahu pertanyaan apa yang sedang mereka cari. Alat yang bisa “melihat besar” tidak otomatis tahu apa yang penting untuk dilihat. Yang menentukan itu adalah sejarawan — dengan kerangka teoretisnya, intuisi terhadap sumbernya, dan kepekaan terhadap konteks yang tidak bisa direplikasi model statistik mana pun.
AI bukan orakel yang memberi jawaban. Ia adalah macroscope yang memperluas jangkauan — tapi tetap membutuhkan mata yang tahu ke mana harus melihat, dan tangan yang bersedia memeriksa apa yang ditunjukkannya. Untuk peneliti sejarah Indonesia yang bekerja dengan arsip yang kaya dan belum tergarap, kombinasi itu bukan kemewahan; ia adalah prasyarat agar AI benar-benar berguna, dan bukan sekadar sumber kekacauan yang terdengar meyakinkan.
Ada satu kalimat yang sering saya katakan kepada siswa-siswa saya dulu, ketika mereka mulai panik melihat seberapa banyak yang harus mereka baca: jangan pernah percaya pada satu sumber sebelum kamu memeriksanya. Prinsip pedagogis sederhana itu, ternyata, adalah kerangka kerja terbaik yang bisa kita bawa ke era AI. Bedanya hanya satu — sekarang sumber yang harus diperiksa termasuk asistennya sendiri.
Daftar Pustaka
Gonzalez Garcia, G., & Weilbach, C. (2023). If the sources could talk: Evaluating large language models for research assistance in history. https://arxiv.org/abs/2310.10808
Graham, S., Milligan, I., & Weingart, S. B. (2016). Exploring big historical data: The historian’s macroscope. Imperial College Press.
Henriot, C. (2025). The AI-augmented research process: A historian’s perspective (HAL preprint No. halshs-05117443v4). HAL Open Science. https://shs.hal.science/halshs-05117443v4
Hufe, L., Griesshaber, N., Greif, G., Eck, S. O., & Torr, P. (2026). Towards the AI historian: Agentic information extraction from primary sources. https://arxiv.org/abs/2604.03553.
Lee, H.-P., Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., & Wilson, N. (2025). The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. Dalam Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25) (Artikel 1121, hlm. 1–22). Association for Computing Machinery. https://doi.org/10.1145/3706598.3713778
Levchenko, M. (2025). Evaluating LLMs for historical document OCR: A methodological framework for digital humanities. https://arxiv.org/abs/2510.06743
Mohamed, S., Png, M.-T., & Isaac, W. (2020). Decolonial AI: Decolonial theory as sociotechnical foresight in artificial intelligence. Philosophy & Technology, 33(4), 659–684. https://doi.org/10.1007/s13347-020-00405-8
Moretti, F. (2000). Conjectures on world literature. New Left Review, 1, 54–68. https://warwick.ac.uk/fac/arts/english/currentstudents/undergraduates/modules/fulllist/special/globalnovel/moretti-conjectures-nlr_1.pdf
Murugaraj, K., Lamsiyah, S., During, M., & Theobald, M. (2025). Automating historical insight extraction from large-scale newspaper archives via neural topic modeling. https://arxiv.org/abs/2512.11635
Poy, L. (2025, August 26). Using NotebookLM for research with digitised historical newspapers. Lucas’s Substack. https://lucaspoy.substack.com/p/using-notebooklm-for-research-with
Stewart, S. D., & Sinha, S. (2025). Retrieving information from unstructured historical sources using large language models. Computational Humanities Research, 1, e17. https://doi.org/10.1017/chr.2025.10019
Sui, P., Duede, E., Long, H., & So, R. J. (2024). Critical confabulation: Can LLMs hallucinate for social good? https://arxiv.org/abs/2511.07722.















Komentar